Writing Structured Query Language (SQL) is a daily part of life at 4CDA. On a typical data analytics project it is common to receive many different data sources that need to be combined into a single data source and then analysed and reported on. This typically involves setting up a database in our own environment or that of our clients where we can automate the ingestion, structuring and analysis of data from various sources.
There is a lot of relational database technologies on the market, both proprietary and open source that can be used for data analysis. Popular proprietary relational databases technologies include Oracle, Microsoft SQL Server, IBM DB2, Teradata and SAP HANA; open source alternatives largely consist of MySQL, MariaDB and PostgreSQL.
What is PostgreSQL?
PostgreSQL is an open source, ACID compliant, transactional, object-relational database management system (ORBDMS). With ties back to the University of California where it began life as the POSTGRES project in 1986.
PostgreSQL has risen to prominence and is one of the go-to database solutions in modern times due to its strong reputation and open source status.
Below is some of the reasons why we like PostgreSQL for data analytics at 4CDA.
#1 – It’s free
PostgreSQL is released under the PostgreSQL License which is similar to the MIT or BSD licenses. This makes PostgreSQL free to use for commercial purposes as long as the copyright notice and license information appears.
PostgreSQL can match and in some cases exceed functionality that other competing closed source database solutions such as Microsoft SQL Server, Oracle, IBM and SAP provides. Why pay excessive licensing fees when you can get a managed version of PostgreSQL with most cloud vendors? (Amazon, Azure, etc.).
For a recent project, we saved the client a considerable amount of expense by suggesting the use of a AWS PostgreSQL RDS database instance instead of a Microsoft SQL Server database running on AWS EC2.
#2 – It can run anywhere
PostgreSQL is truly cross-platform and has been for a while – this means the database technology will run on Windows, Mac and various Linux distributions comfortably.
This provides great flexibility for most clients and the with the push to DevOps and infrastructure-as-code, where PostgreSQL’s command line interface makes it easy to setup and configure your database via code.
#3 – Makes working with CSV and JSON pain-free
Data file formats comma-separated values (CSV) and JavaScript Object Notation (JSON) are two of the most commonly seen data formats encountered on data analytics projects.
The out-of-the-box functionality for working with CSV and JSON that PosgreSQL provides is excellent, especially in comparison with how tedious it is to work with these common formats in other proprietary database technologies such as SQL Server, Oracle, etc.
CSV
Comma-separated values or CSV is one of the most widely used data formats. It is the commonly provided export format from most software appliances and a common format provided by clients in data analytics projects.
PostgreSQL makes working with CSV a pain-free experience – you can easily import CSV or export to CSV using native commands such as the useful COPY command.
For example, the simple process of importing and exporting CSV data sources is simple in PostgreSQL and at a high-level is a two stage process involving:
Create a table that mimics your CSV structure
CREATE TABLE post_codes
(POST_CODE char(4), LATITUDE double precision, LONGITUDE double precision, CITY varchar, STATE char(2), POST_CODE_CLASS varchar);Copy data from CSV to your table
COPY post_codes FROM '/path/to/csv/POST_CODES.txt' WITH (FORMAT csv);Now compare that exact same process in a non-free database tool like Microsoft SQL which has no native CSV import/export, experiences text parsing issues like truncating text fields and has poor error handling / messaging when something goes wrong.
The lack of CSV-related functionality leads to instances where people write additional code to handle CSV import/export which should be an out-of-the-box capability inbuilt to the database management system itself.
JSON
The JavaScript Object Notation (JSON) file format has grown to prominence alongside CSV as one of the most commonly used data interchange formats especially with its heavy usage in asynchronous client-server communications prevalent in the web (e.g. data providers typically provide you access to their data feeds via REST API serving you JSON data accessible by a secured endpoint).
PostgreSQL has two datatypes specific to working with JSON including JSON and JSONB. The two data types are almost identical in terms of the functionality you get with the key difference being that JSONB stores data in a binary format which is more efficient and supports indexing.
To illustrate some of PostgreSQL’s JSON functionality, imagine we are provided with a JSON related to a mining truck and its parts.
To import this quickly into PostgreSQL we might run the following:
create unlogged table truck_parts_import (doc json);Once we have our JSON-imported data in a table in a format that we like, we can query the data, including querying for specific keys.
SELECT data->'name' AS name FROM mining_trucks; Or filtering.
SELECT * FROM mining_trucks WHERE data->'status' = 'Operational'; Or if using the JSONB we can check for containment or existence of a particular value in our data.
/* Containment - check if one document is contained in another */
SELECT data->'maintenanceStatus'
FROM mining_trucks
WHERE data->'maintenanceStatus' @> '["Scheduled", "Delayed"]'::jsonb;
/* Existence - check whether object key or array element is present */
SELECT COUNT(*) FROM mining_trucks WHERE data ? 'status'; A full set of JSON-related functionality is available here.
In comparison, most proprietary databases, including big names like Microsoft, Oracle and SAP, have no support for JSON at all.
#4 – The Array datatype
PostgreSQL has a wide array of datatypes and it is one of the databases core strengths.
The Array datatype is a particularly powerful and useful data type – it allows columns of a table to defined as variable-length multidimensional arrays. Arrays can contain any datatype you like including other arrays!
Arrays are very useful in application development (e.g. storing tags related to a blog post in a blogging website) and in data analytics where array types can do nifty things such as:
- Aggregating multiple data values across groups for efficient cross tabulation
- Perform row operations using multiple data values without having to use a join
- Represent array data from other applications or feed array data to other applications, e.g. provide array data to a web app, consume array data from a micro service
- Store machine learning model weights as 2D arrays of numbers.
More information on the array data type is available here.
Closed source database management systems like Microsoft SQL Server do no support a native array data type.
#5 – Regular expressions or regex
Regular expressions, commonly known as regex or regexp, is a sequence of characters that defines a search pattern, e.g. ^[1-9][0-9]?$|^100$ returns numbers between 0 and 100, not including 0.
Text processing is a common part of data analytics work, especially when you are cleaning and combining data for analysis. PostgreSQL comes with regular expression commands natively that can be used for a variety of data analytics use cases.
Some examples of using PostgreSQL for regular data analytics use cases includes:
Find all SKU’s that have a valid SKU format.
SELECT REGEXP_MATCHES(my_skus, E'^[a-z0-9A-Z]{10,20}$') FROM my_sku_table;Find all words in a string with at least 10 letters.
SELECT REGEXP_MATCHES(my_string, E'\\y[a-z]{10,}\\y', 'gi') FROM my_table;More information on PostgreSQL regex can be found here.
Closed source database management systems like Microsoft SQL Server do not have regex capability natively and require the installation of third party packages.
#6 – Dollar-quoted string constants
Dollar-quoted string constants or “dollar quoting” is a method provided by PostgreSQL for writing string constants. The dollar symbol ($) is used to wrap the contents of the string content (e.g. $ "my string" $).
Dollar-quoted string constants are not a part of the SQL standard, but are a more convenient way to write complicated string literals as it can handle strings within strings – this is particularly useful for writing dynamic SQL which is commonly required in data analysis and is error-prone using apostrophes.
More error-prone and confusing way of writing dynamic SQL using apostrophes where you have to do manually quote and escape strings within strings.
CREATE FUNCTION public.example() RETURNS varchar(100)
LANGUAGE plpgsql
AS
'
BEGIN
RETURN '' I have some text with ''''quotes'''' in it'';
END
'Compared with the cleaner, less error-prone “dollar quoting” method.
CREATE FUNCTION public.example_2() RETURNS varchar(100)
LANGUAGE plpgsql
AS
$body$
BEGIN
RETURN $mytext$I have some text with 'quotes' in it$mytext$;
END
$body$More information on “dollar quoting” from the official PostgreSQL doc’s can be found here.
#7 – Comes with stats capabilities out of the box
While not a replacement for a robust statistical programming language like R, Python or Julia, PostgreSQL comes with a load of useful statistics capabilities inbuilt and usable via SQL.
Some examples include:
corr(Y, X)– Pearson’s correlation coefficientregr_count(Y, X)– number of input rows in which both expressions are non nullregr_intercept(Y, X)– y-intercept of the least-squares-fit linear equation determined by the (X, Y) pairsregr_slope(Y, X)– slope of the least-squares-fit linear equation determined
More information on aggregate functions for statistics can be found in the official PostgreSQL doc’s here.
#8 – Ordered-set aggregate functions
PostgreSQL has a whole host of aggregate functions from general-purpose aggregate functions, aggregate functions for statistics, hypothetical-set aggregate functions and one of our favourites being ordered-set aggregate functions.
Ordered-set aggregate functions, also known as “inverse distribution” functions, are particularly useful for statistics use cases.
As an example, take the Box-Meuller transform. Which is a pseudo-random number sampling method for generating pairs of independent, normally distributed random numbers given a source of uniformly distributed random numbers.
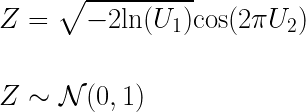
In PostgreSQL, using ordered-set aggregate functions, we can apply the Box-Meuller transform to approximate a log normal distribution and then take the mean and median.
WITH uniform AS
(
SELECT
random() as uniform_1,
random() as uniform_2
FROM generate_series(1, 1000)
),
dist AS
(
SELECT
exp(sqrt(-2 * ln(uniform_1)) * cos(2* pi()* uniform_2)) AS log_normal
from uniform
)
SELECT
percentile_cont(0.5) WITHIN GROUP (ORDER BY log_normal) AS log_normal_median,
exp(0) as expected_log_normal_median,
avg(log_normal) AS log_normal_mean,
exp(0.5) as expected_log_normal_mean
from dist;A Developers’ and Data Scientists’ database
These are just some of the reasons why we like using PostgreSQL for data analytics and application development at 4CDA. In truth, these reasons only begin to scratch the surface of what PostgreSQL is capable of. The database is constantly improving with each release bringing new features and bug fixes – it has come a long way from humble beginnings.
We plan to share tutorials, tips and tricks on PostgreSQL on an ongoing basis as we discover interesting ways it can be used to solve business problems.